Its the weekend, which means another section of the guide…
Building the Server
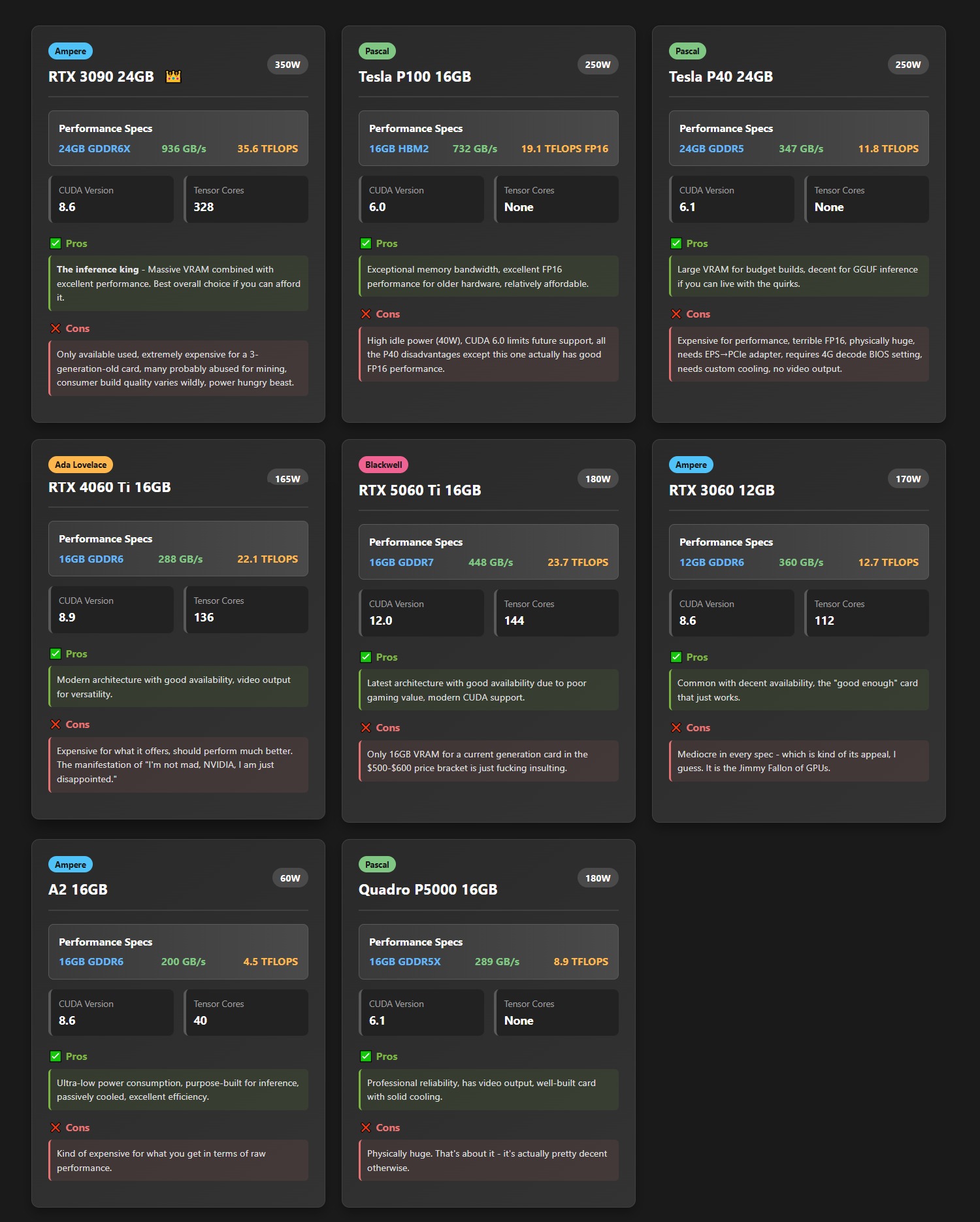
I will go through and build an AI server out of parts that I have and document the process.
Note: this part of the guide is going to assume that you are able to troubleshoot hardware issues yourself. It will not contain any troubleshooting information. The guide assumes you can handle finding out if hardware is incompatible or broken and to replace it as needed. It is not meant to be comprehensive but merely informative of the process.
All the parts have arrived! Now we get to do the real fun stuff.
First step is to make sure it boots as-is. The first time takes a while it has to go through its checks and self-training again and this will happen every time I add or remove a part. Once that is confirmed, the RAM goes in and then we set the BIOS. Reset to defaults first in the menu and reboot again. The most important part in here is CSM gets turned OFF and then UEFI boot ON. Second is the MMIO or Above 4G Decode, which must be ENABLED. Set the rest of the stuff in here to your liking. After another reboot proves we didn’t break anything, shut it down, pull the GPU out that came with it, and put the new (used) one in. If you have more than one, pick one to be the primary, install that in the same slot as the one that came with it, and hook up any power connectors needed. If you have more than one GPU, leave all but the primary one out at this point.
About cooling and power for P40/P100 style datacenter cards
If you have a P40 or P100 you will need to attach a fan to it. There are different ways of doing this. I 3D printed an adapter and attached a 75mm blower on to it, and hooked that up to a temperature sensing fan controller. Another 3D printed part holds the NTC temp probe on the card. The best place to mount the temp probe is at the front on top, as it is metal, it is where the hottest space is that you can find on the outside of the card, and it already has screw holes and screws you can use. On top of that you will need 8 pin PCIe to 8 pin EPS power converters and a way to power the fan. You will have to find the adapters yourself, they are about $10-$15, and if you have limited PCIe power connectors you will need to get a splitter for them. You will need two 6 pins, an 8 pin split to two 6 pins, or two 8 pins for each P100 or P40 card in your system. For the fan, some people just pull the connectors pin from the fan connector and shove them into the 12V and GND inside the PCIe or molex power, but I cut apart a SATA power connector and soldered on headers for this one.
OS Install
Another note: this guide is not a comprehensive guide on Linux use. I assume you will understand things like command line and how to solve software problems.
Now we will install Ubuntu Server. Why Ubuntu? Because it works and I am used to it. I couldn’t give two shits about Linux distros, so if you are big on Arch or whatever, use that, but any instructions in the guide are for Ubuntu. Also, I am not going to install a desktop environment, because I don’t need one. Once it is working ssh will be the primary mode of administration and it won’t even have a monitor.
Download the latest point release of Ubuntu Server LTS and put it on a USB stick, using Rufus or something else to make it bootable.
When you install the OS, you will need to enable a few things, the rest is at your discretion:
- OpenSSH
- Third party drivers
Once the OS has installed and booted, make sure to update:
sudo apt update
sudo apt upgrade
At this point we can just SSH from another machine and do things there. Find the IP address of your LLM box—it will be given upon login or by typing
ip addr show
and you can ssh into it. I suggest setting it as a static IP on your router.
Now we will get the nvidia ecosystem sorted out. Shut down and put any additional GPUs in your box if you have them. When booted type:
sudo ubuntu-drivers devices
Find the recommended driver in the list and install it.
sudo apt install nvidia-driver-575
Reboot.
Next we install CUDA toolkit. Go here and find the instructions, then type what they tell you into your terminal
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-9
nano ~/.bashrc
Paste this at the end of .bashrc
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Now check that its all good:
source ~/.bashrc
nvidia-smi
nvcc -V
And it’s ready to go!
If you want to get an LLM running right now:
wget -O koboldcpp https://github.com/LostRuins/koboldcpp/releases/latest/download/koboldcpp-linux-x64
chmod +x koboldcpp
Note: If you use a P40 or P100 add this to the following commands:
--usecublas rowsplit
If you have 24GB VRAM:
./koboldcpp https://huggingface.co/bartowski/google_gemma-3-27b-it-GGUF/blob/main/google_gemma-3-27b-it-Q4_K_M.gguf --mmproj https://huggingface.co/bartowski/google_gemma-3-27b-it-GGUF/blob/main/mmproj-google_gemma-3-27b-it-f16.gguf --contextsize 8192 --gpulayers 999
If you have 12GB or 16GB VRAM:
./koboldcpp https://huggingface.co/bartowski/google_gemma-3-12b-it-GGUF/blob/main/google_gemma-3-12b-it-Q4_K_M.gguf --mmproj https://huggingface.co/bartowski/google_gemma-3-12b-it-GGUF/blob/main/mmproj-google_gemma-3-12b-it-f16.gguf --contextsize 8192 --gpulayers 999
When that loads, go to the server’s ip address with :5001 at the end in a web browser, and talk to your LLM!
EDIT:
Koboldcpp will work with any OpenAI compatible client by using the URL + port with /v1 at the end as the endpoint. Example: http://192.168.1.44:5001/v1
EDIT 2: DO NOT INSTALL OLLAMA it is a giant pain in the ass to get off of your system. You have been warned.