Oh, buddy. Here we go.
Long story short, I’m gonna build out an AI model on a home hosted server. The inspiration came from @amal, by way of the following threads. I’m starting a new thread because I don’t want to clutter up the existing ones with my random attempts / thoughts / musings, and because you can often learn more watching an idiot fail, than an expert succeed (and I AM an AI idiot).
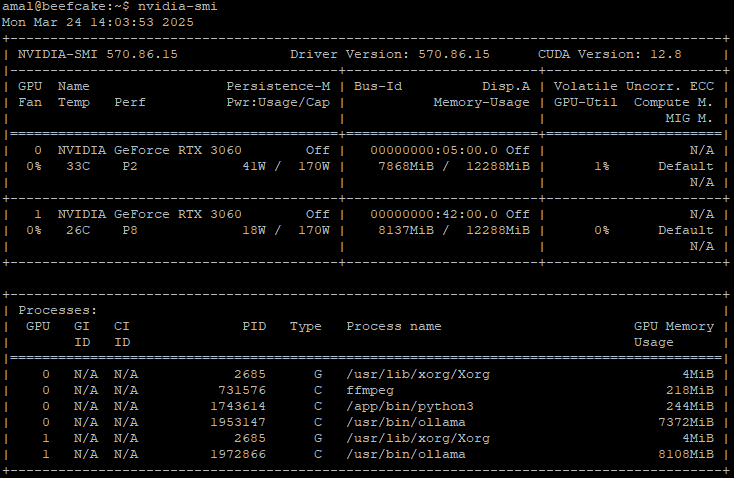
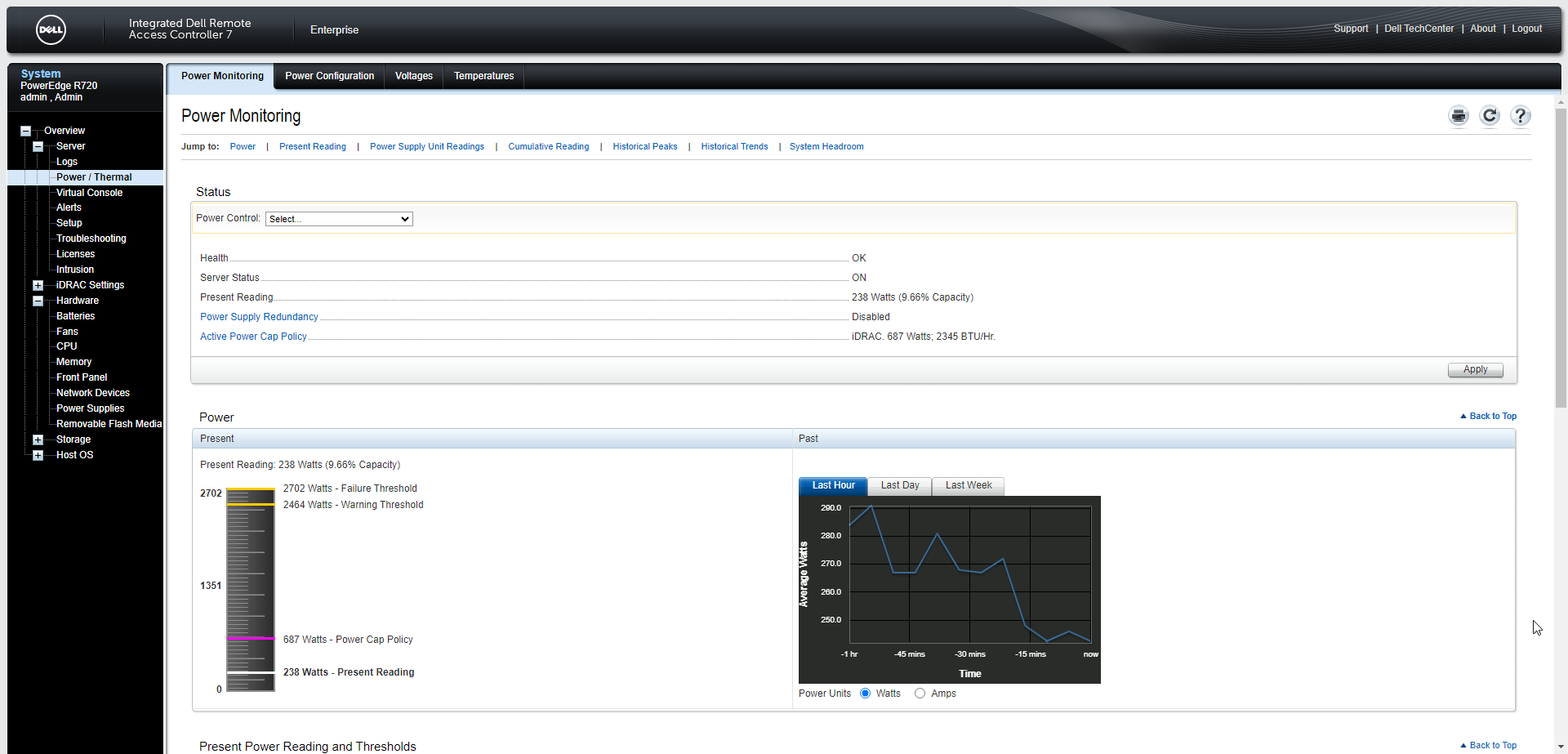
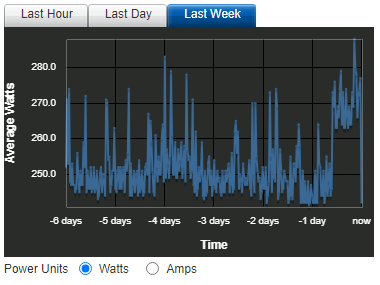
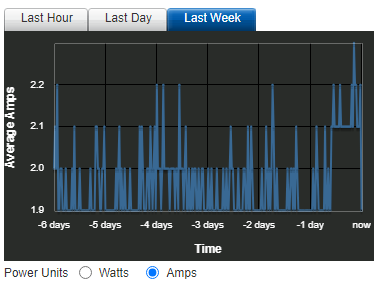
THIS is Amal’s AI thread that got me started, and THIS is how Amal stuffed 3060 GPUs into his R720 server to accomodate the AI build.
So first thing, I bought a R720 dell server for 219.99 (Ebay) which ended up at 241.99 with tax. It’s sitting here in front of me in all it’s enterprise level goodiness.
First impressions, bigger than I thought, followed by damn, that’s heavy.
I have 12 of 24 slots of RAM at 8gb apiece for 96gb ram total. I seriously thought about filling the rest up, but frankly, I don’t think I can really use what I’ve got now without running multiple VMs, which I don’t intend to do.
I have the dual E5-2630 at 2.6GHz processors. Not the best, not the worst, probably be more than I need anyways.
These servers use riser cards to connect GPUs to the PCI. The first one (#2) always supports x16 speed, the second one (#3) supports multiple x8 or on an optional card for a single x16. I have the first option, so if I ever want a second GPU, I’ll need to swap that card out. But not today.
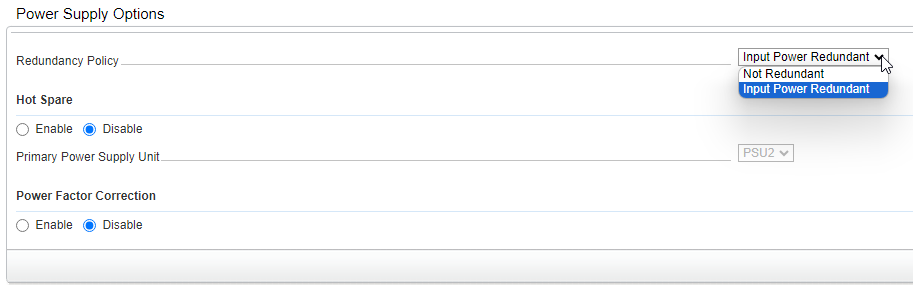
I have the dual 750w power supplies. They’re plug and play hot swappable and as such you’re not going to get anything other than factory. Speaking of which, they did offer 1100w power supplies which are definitely recommended for GPU usage, so I’m going to pick up a pair of those next.
For storage I’ve got 8x 600GB hard drives (overkill) and don’t have the optional SD card (no biggie). There’s also a DVD drive, which kinda suprised me, wasn’t expecting it, but not complaining.
Other than that, per the seller, it’s supposed to be running Windows 10, but I’ve not booted up yet to check and see.