I didn’t think this would work, but amazingly it does: you can have more than one EM UID on a single implant. And it works pretty good too!
So, a bit of background: as you may know, my SiRFIDaL RFID login software for Linux can work with two different kinds of readers: repeating (or continuous) readers and one-shot readers. The former send whatever is in the field repeatedly (or can be polled continuously), while the latter only send the UIDs of tags that come into the field once.
Repeating readers are nice, because not only is it possible to match the UIDs against registered users, it’s also possible to determine whether the tag is still present or has left the field for additional functionalities.
For instance, if I “short-present” my implant to the reader, it logs me in, and once I’m logged in, if I “long-present” my implant, it locks my screen. In other words, repeating readers can be used to authenticate the user and also track their presence, something that’s not possible with single-shot readers.
I also have this project of creating a smart chair that logs me in when I sit down and locks my screen when I get up, using an implant in my butt. For that, I need a repeating reader under my chair. Unfortunately, the only readers suitable for this project are long-range LF readers such as the ACM08Y or ACM26C - and those are typically one-shot, dumb (very dumb) serial readers. I’ve searched far and wide for configurable or pollable long-range readers, but sadly to no avail. So my butt implant project has been on hold… until today ![]()
I’ve been wanting to modify the aforementioned readers to turn them into repeating readers. But it’s not very easy because the electronics are potted in a metric ton of epoxy, and I’m sure I’ll destroy them if I try to expose the innards.
But then I thought: those readers only report tags coming into the field once. But they maintain the field while the tag is present. So what they must be doing is receive the tag’s UID continuously, and only report when the UID changes. After all, that’s what EM tags do: as long as they’re powered, they send their UID over and over.
Maybe, just maybe, the readers’ firmware doesn’t actually care that the tag leaves the field, just that the UID is different from the previous one. So if I had a tag that alternated between two UIDs, I could force the reader to report the UID at each change and track when the stream of UIDs stop to know that the tag has left the field.
And then it hit me: the T5577 is capable of doing that! All the chip does is send a sequence of bits stored in part of its memory over and over. I could simply encode a second, different sequence after the first one and configure the chip to send twice as many bits - in effect getting it to send a long, custom sequence composed of two valid EM sequences.
So I hand-programmed my xEM to do that, and sure enough, my readers started spewing out alternating UIDs at high speed continuously. Success!
So here’s the technical explanation on how to do it (note that you need a Proxmark3 for this):
Firstly, a word on EM bit sequence encoding: if you look at this helpful page (), you learn that the sequence is composed of 9 start bits, followed by 10 nibbles + parity that encode the 5-byte UID, followed by one parity nibble, followed by 1 stop bit:

So let’s say we want the first UID to be 0xDEADBABE01 and the second UID to be 0xDEADBABE02. They get encoded as follows:
-
DEADBABE01:
Bin: 111111111 1101 1 1110 1 1010 0 1101 1 1011 1 1010 0 1011 1 1110 1 0000 0 0001 1 0001 0
Hex FFEFB4DDE97E8062 -
DEADBABE02:
Bin: 111111111 1101 1 1110 1 1010 0 1101 1 1011 1 1010 0 1011 1 1110 1 0000 0 0010 1 0010 0
Hex: FFEFB4DDE97E80A4
Now then, how to hand-program your T5577 with two UIDs?
Simple: first, program the T5577 as an EM41xx normally with the Proxmark3 with the first UID:
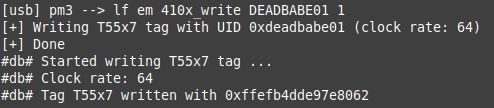
This command writes the 64 bit sequence for DEADBABE01 in block 1 and 2, and configures fhe correct bit rate / encoding / mode… in block 0:
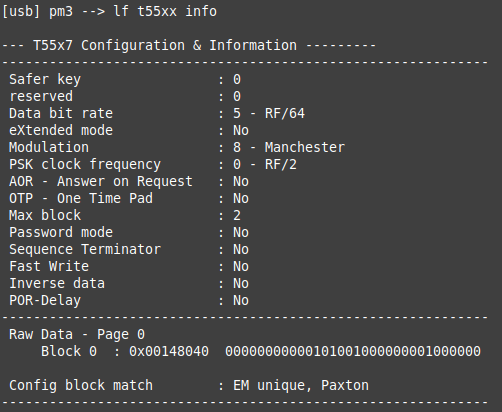
Crucially, it sets MAXBLK to 2. If you look in the datasheet, it says this:

So this is correct: configured as a normal EM, the T5577 will transmit the 32-bit blocks 1 & 2 over and over.
So what we need to do now is program the sequence for the second UID (DEADBABE02) into block 3 and 4, and bump up MAXBLK to 4, so that the T5577 will transmit blocks 1, 2, 3 and 4 over and over.
Of course, there is no provision in the Proxmark3 client to do this. So we need to do it by hand.
Firstly, programming block 3 and 4: split the DEADBABE02 sequence into 2 32-bit words: FFEFB4DD and E97E80A4.
Then program blocks 3 & 4 with the Proxmark3 client manually:
![]()
![]()
Finally, adjust MAXBLK in block 0: if we look in the T5577 datasheet again, here’s the bitfield in block 0:
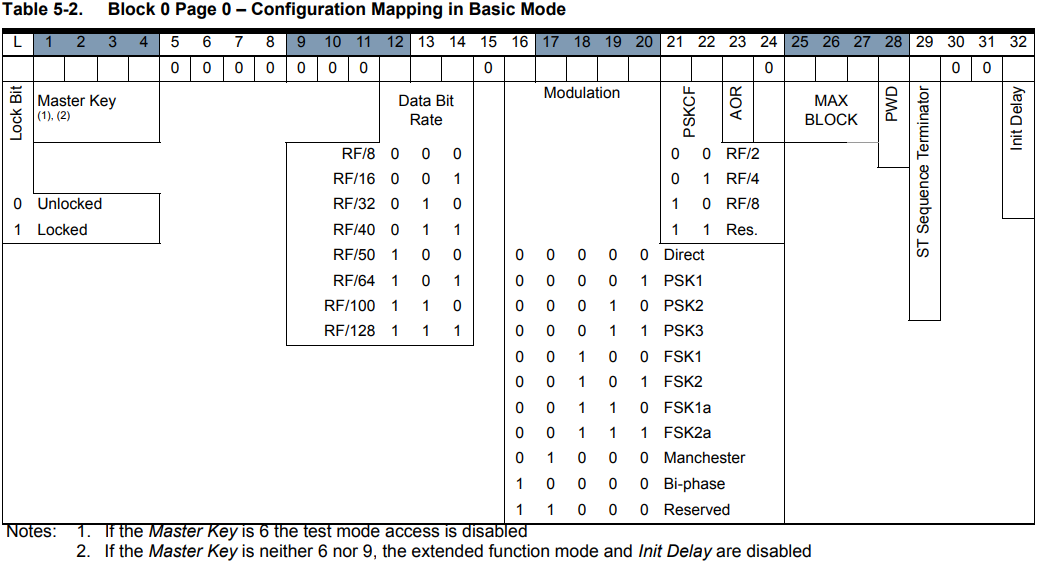
So we see MAXBLK is encoded in bits 25, 26 & 27.
We already have the current value of block 0 from the lf t55xx info command above. The MAXBLK bits are in bold:
…
Raw Data - Page 0
Block 0 : 0x00148040 00000000000101001000000001000000
…
So we need to change the binary value of block 0 to:
00000000000101001000000010000000
which is 0x00148080.
To do this, program that value in block 0:
![]()
Confirm that the new value has been programmed correctly
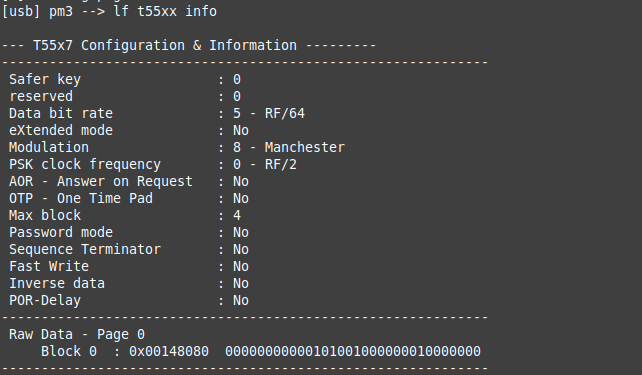
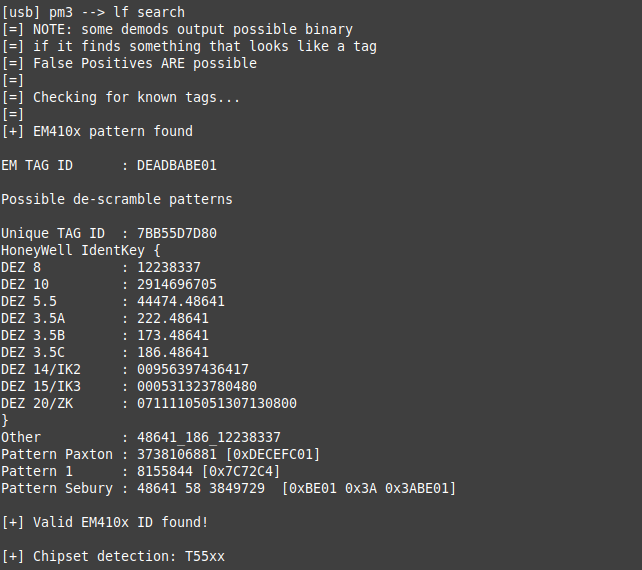
Note that this time, lf t55xx info does not report the tag as a valid EM anymore. However, lf search still does (but only interprets the first UID because it doesn’t expect anything beyond the first sequence:
And now, if you present the tag to a dumb reader, it’ll spew out the two UIDs alternatively at high speed:
...
DEADBABE01
DEADBABE02
DEADBABE01
DEADBABE02
DEADBABE01
DEADBABE02
...
It even works with 3 UIDs: there are 7 data blocks in a T5577, so you can also use block 5 and 6 to encode a third UID, and adjust MAXBLK to 6. But I noticed some of my readers get a bit iffy with 3 UIDs. 2 work fine though.
Basically, it’s exactly like the reader was in The Matrix and Neo was presenting his 2 implants one after the other alternatively at super-high speed. So it’s not even an invalid sequence of UIDs! But some readers might cause trouble, either because the firmware decides to do something then wait until the field clears after reading a UID, or because the link to the computer is too slow (keyboard wedges for instance). After all, they were never created to read Neo’s implants at the speeds Neo is capable of ![]()
But on the readers I’ve tried this on, it works dandy. Those are:
- ACM08Y (dumb reader, Wiegand, RS232 or RS485)
- ACM26C (same as ACM08Y)
- Sycreader R60D (keyboard wedge)
- Elatech Multitech TWN4 (PC/SC reader)
How useful is this likely to be “in the wild”?
Well, provided the reader you want this to work on doesn’t choke on the rate of UID change, it should work on any reader. You can even accommodate difficult readers: say one of them (your home’s front door reader) works fine with either the first or the second UID, but another (the door reader at your workplace perhaps) only triggers on the first UID but not on the second one because it pauses after reading an invalid UID, then simply reorder the UIDs on the T5577 so they get presented in the right order.
Anyway, it’s a fun hack to try, and it’s a cheap way to extend the usability of your xEM or flexEM. I hope you’ll enjoy playing with this ![]()